Managing Cluster Resources Made Easy with Slurm: an HPC Story with Damien François
Published on 17/04/2023
Can you introduce yourself and your role in the CÉCI?
I graduated as a civil engineer in 2002. Then I got my thesis in machine learning in 2007 and continued with a postdoc in economic valuation of research. I started my career as an HPC sysadmin at the end of 2010 in the Centre for Intensive Computing and Mass Storage (CISM) at UCLouvain where I have been directly involved in CÉCI activities. I participated in the implementation of the common login system and I helped evaluate the options for the choice of the job manager for the first CÉCI machine. More recently, I participated in the implementation of the common storage. Currently, I do both user support and systems management. So I participate in writing and updating the CECI documentation [1] , I give some training sessions and do a little of consulting. And I take part in the deployment and maintenance of physical and virtual HPC infrastructures at UCLouvain.
Can you explain to our reader what Slurm is and does? What are the benefits for the users?
Slurm is the job scheduler and resource manager of the clusters of the CÉCI. It decides which computing resources are allocated to which job at which moment, isolates jobs one from another, and sets up the environment for parallel computing. They are many advantages of using a workload manager like Slurm: it ensures jobs get exclusive access to resources, it shares resources fairly among users, and it makes it somewhat easy to start a parallel job.
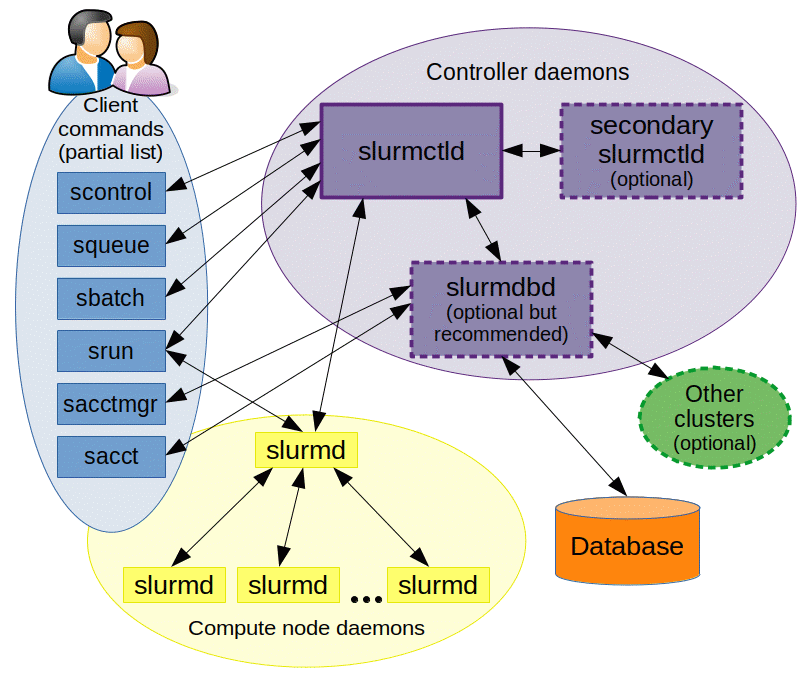
Slurm architecture [2]
And for system administrators? What are the advantages of Slurm compared to other workload managers?
Not only is Slurm free and open source but it also is very stable, has an extensive documentation, a strong community, and many configuration options that can be extended by scripts or plugins. It is often also found to offer more performance than others in terms of responsiveness and job throughput. It has now become the de facto standard for large and small clusters.
How did the story of Slurm begin in the CÉCI?
In early 2011, the first CÉCI machine "Hmem" was procured with compute nodes with up to 512GB RAM, which was huge at the time. The machine needed a scheduler that properly managed memory. At that time, SGE was popular in CÉCI universities. However, SGE's future was uncertain with the buyout of Sun by Oracle. Moreover, it did not offer a convincing way of ensuring memory allocation to jobs and was complicated to explain to users. I was tasked with evaluating Slurm. It was at version 2.5 at the time, so approximately 15 major versions ago(!), and it was found to be a good solution at that time. So, Hmem was set up with Slurm, followed by all 10 subsequent CÉCI clusters, and probably all future clusters for the foreseeable future.
What were the main challenges and difficulties encountered in implementing Slurm?
The main challenge was getting users to embrace Slurm and forget SGE. We had to write a lot of documentation and do many training sessions. Furthermore, some features were not available at the beginning. The most annoying one were the job arrays for users and bash completion for admins. Job arrays are the capability to submit a large number of "parametrised" jobs that all are identical except for some parameter. Bash completion is an aid in the command line that auto completes commands and their arguments, typically with the TAB key on the keyboard, saving lots or typing and guessing. However, job arrays were shipped in the next version, and we developed a Bash completion script ourselves. That script was still being shipped with Slurm up until 2022. On a different note, Slurm evolves quickly, so it is not easy to keep up with new features. Our trick is to be active in the Slurm community on StackOverflow and to monitor their bug tracking system and mailing lists closely.
How is the feedback from users regarding Slurm?
Everyone is happy that Slurm was chosen for CÉCI clusters as it has become the most popular resource manager all over the world. Very few use cases are not covered by Slurm, and most of the time, we are able to provide a workaround. The main complaint we keep having is that jobs wait too long in the queue, which depends more on the available hardware than the scheduler.
How do you see the future of Slurm/workload managers?
From a user perspective, workload managers will probably be shadowed by workflow management systems that allow submitting jobs to multiple clusters, and at the same time dispatch the data, consolidate the results, etc. In 2022, we organised a workshop related to that topic, whose videos can be found on the CÉCI Youtube channel [3].
They will also evolve to encompass more use cases than the usual MPI HPC application, and open up to Machine Learning workflows with more heterogeneous, and time-varying, resource requirements, and a more interactive usage than the traditional batch job.
From an admin perspective, the workload management systems will be more and more compatible with, and integrated to, the whole "container" ecosystem. They will also make it easier and easier to interact with web services or mobile apps, moving away from the usual, but sometimes rebutting, SSH command line.