User Story: Emotionally Intelligent AI - From University Research to Market Innovation with Alfasent

AI is Everywhere, but Understanding Emotion is Hard
A Large Language Model (LLM) is a type of generative AI designed to understand and produce human language. These models are increasingly used in various aspects of society. AI now shows up in everyday applications, from chatbots to customer review analysis. However, despite the capabilities of large language models, truly understanding human emotions remains a challenge.
Professor Véronique Hoste leads the LT3 language and translation team at Ghent University, where she specialises in machine learning for natural language processing. A major focus of her team is improving the performance of large language models in Dutch. They face a core challenge: large language models perform better in English than in Dutch, which makes it harder to capture cultural nuance and local context.
Why AI Needs to Speak Dutch
Prof. Hoste emphasises that current language models are largely English- and Anglo-centric, both in linguistic coverage and in the world knowledge they encode. This limits their value for languages such as Dutch. A recent PhD project on irony detection showed that generative models contain struggled with explaining the irony in Dutch tweets while performing much better on English ones.
Prof. Hoste: “I believe leveraging technology like ChatGPT in various contexts can be beneficial. While it performs well in many applications, it struggles with culturally specific tasks, like question answering or storytelling. This cultural sensitivity is crucial for effective human-machine interaction. It's important to incorporate knowledge of the Dutch language into these systems. Otherwise, users may become frustrated if the system fails to meet their needs, which would be unfortunate. Tailoring technology for Dutch could significantly improve its effectiveness.”
From Sentiment to Emotion: Teaching AI Cultural Sensitivity
Prof. Hoste and her team's research has led to many practical applications, including the automatic detection of sentiment in online reviews. Another critical application involves understanding more fine-grained emotions, which are often culturally shaped and highly context-dependent. The way we express and discuss emotions can differ significantly from one culture to another. This consideration is crucial for effective customer relationship management.
Beyond customer reviews, understanding culturally specific emotions is vital. As Hoste warns, robots and digital assistants that fail to recognise emotions risk losing users’ trust.

Prof. Hoste: “When considering practical aspects of human-computer interaction and human-robot interaction, this cultural sensitivity becomes essential. It's necessary to embed this understanding into systems. Without it, communication can break down; users may stop interacting with robots that fail to exhibit empathy because they do not recognise or respond to the user's emotional sensitivity.”
From Research to Market: the birth of Alfasent
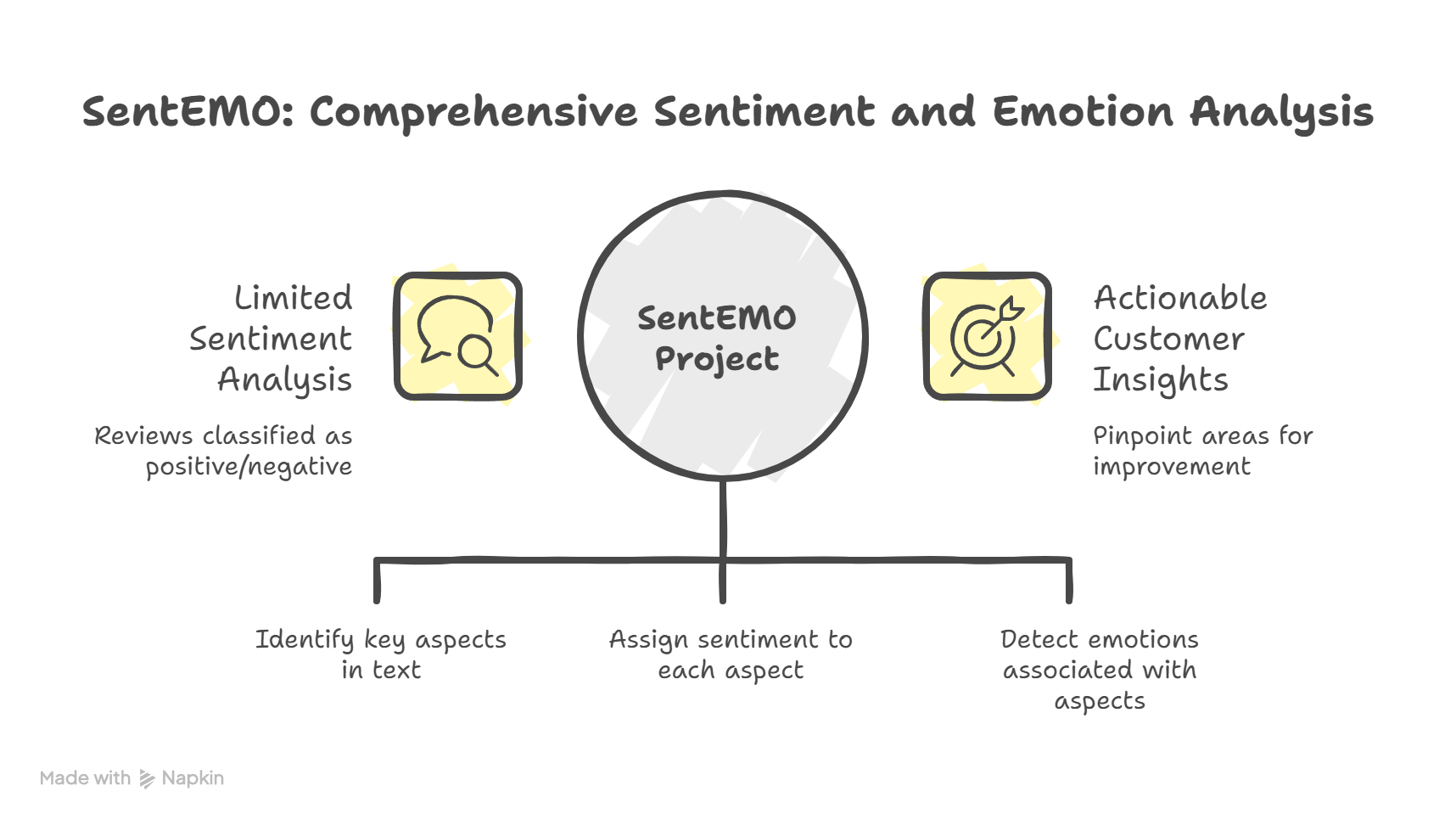
A significant initiative in advancing sentiment and emotion analysis was the SentEMO project [1], launched by the LT3 team of Ghent University together with Arteveldehogeschool. Led by Prof. Hoste, the project built further on a decade of research in the domain of fine-grained sentiment analysis and aimed to empower companies with actionable insights derived from their text data.
Many existing tools classify reviews only as positive or negative, ignoring that a single review may contain both positive and negative sentiments. SentEMO combined aspect-based sentiment analysis (positive, negative, neutral) with emotion analysis (e.g., anger, fear, happiness) using advanced machine learning methods.
Professor Hoste elaborates on the system's purpose: "Our primary objective is to analyse reviews in a more comprehensive manner. For example, consider the sentence: 'The food was fantastic, but the waiter was so rude.' In this case, 'food' relates to positive sentiment regarding quality, while 'waiter' pertains to negative sentiment about service. Our approach involves three key steps: aspect term extraction, categorisation, and sentiment and emotion detection. We also identify the emotions associated with each aspect, providing companies with detailed insights into customer opinions. This information allows them to pinpoint specific areas in their offerings that may require improvement.”
SentEMO received funding from VLAIO (Agentschap Innoveren en Ondernemen) [2], the Flemish government' agency that supports innovation and entrepreneurship in Flanders, while fostering a favourable business climate. VLAIO enables businesses to grow, transform, or innovate through funding and guidance. The LT3 team set up a user committee of companies to ensure the results would be practical applicable. The project was specifically funded through VLAIO's TETRA program, which supports practice-oriented research conducted by universities of applied sciences and integrated programs at universities that benefit businesses and non-profit organisations. Ultimately, the SentEMO project led to the creation of the spin-off company Alfasent.
Practical AI: Choosing Efficiency over Scale
As the team transitioned research into a company setting, practical considerations became essential. Els Lefever, associate professor at the LT3 team, explains: “In the spin-off, we sometimes continue to use more traditional machine learning algorithms, such as support vector machines or transformer-based encoder models, because they fit company needs. There is often a preference for lightweight, faster, and more efficient models that can still deliver strong performance, especially when trained on manually labelled data.”
Prof. Lefever also points out that while generative models can improve output quality, they require substantial investment in large GPU infrastructure, something not every company can afford:
“You don’t always need the biggest model to meet your goals—the key factor is quality data. With well-curated, domain-specific datasets, more traditional machine learning approaches can perform extremely well without the complexity of generative models. Our team also values encoder models trained on manually labelled data, for some tasks, they can be just as effective or even better. These models are smaller, more efficient, and require far less GPU power.”
Why Multimodal AI Requires Supercomputing Infrastructure
Currently, Alfasent primarily focuses on text. Meanwhile, the LT3 team is increasingly focusing on multimodality, combining text with speech and visual signals.
Prof. Hoste: “At times, while the text itself may be excellent, the accompanying image can create irony or convey nuances, highlighting the need for a multimodal approach. Furthermore, emotions are often expressed through these various modalities. This is a crucial component of our ongoing research objectives. To achieve this, we rely heavily on supercomputers as we work with textual, speech, and video data. This significantly increases the data we handle and the processing power required.”

Prof. Lefever adds: “The computing power of the VSC is essential for conducting our research. We need to train models and, where relevant, fine-tune them on new data. Our current equipment, including individual laptops and local servers, simply lacks the capacity to run these experiments effectively. To properly train, fine-tune, and evaluate large language models and other complex models, we really need the computational capabilities provided by the VSC.”
[1] SentEMO Project (January 2021- December 2022) https://lt3.ugent.be/projects/multilingual-aspect-based-sentiment-and-emotion-an/
[2] VLAIO - https://www.vlaio.be/en
Prof. Veronique Hoste

Veronique Hoste is Senior Full Professor of Computational Linguistics at the Faculty of Arts and Philisophy at Ghent University. She is department head of the Department of Translation, Interpreting and Communication and director of the LT3 language and translation team at the same department. She holds a PhD in computational linguistics from the University of Antwerp (Belgium) on "Optimization issues in machine learning of coreference resolution" (2005).
Prof. Els Lefever 
Els Lefever is an associate professor at the LT3 language and translation technology team at Ghent University. She has a strong expertise in machine learning of natural language and multilingual NLP, with a special interest for computational semantics, irony and hate speech detection, argumentation mining, complex reasoning, and ancient language processing.